






抗衡GPU LARRABEE视觉计算有何期待
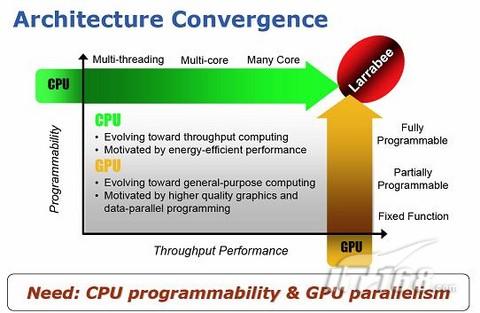
作为GP-GPU规范制定者之一的Intel,虽然目前在传统的GPU领域并不是领袖,但传统GPU已经依靠其现有的结构特长,在高度并行浮点运算速度上赶超CPU。Intel提出视觉计算的概念,让技术和产业方向更为明确,也是Intel对现有GPU产业在多领域发挥作用现状的认可。这不等于显卡产业,GPU的应用与整合技术的发展也不等于显卡产业的灭亡,更应该理解为基于视觉系统整体化应用形式的改变。

视觉计算是什么,Intel几乎是从另一个角度向我们提出万亿次计算、千万亿次计算要带给大家什么?从为万亿次运算准备的Tera-Scale软件开发平台,到现在256核心的Nehalem,以及今后的Larrabee GPU。万亿次运算将指的不仅仅是多核心的CPU,而更早达到这一数字指标的很可能是GPU;更完整展现万亿次运算成果的很可能是“视觉计算”。
Larrabee——INTEL涉足视觉计算的结晶

随着近年GPU踏足通用计算,data re-use的场合越来越多,即使是现在游戏图形运算中时常遇到的post processing,data re-use也是司空见惯的事情,为此GPU厂商也都往GPU里加入可读写的软件管理cache。象最早引入该概念的产品 NVIDIA的G80,它有16个内核(称之为 Streaming Multiprocessor,或者简称SM),每个内核内都有一块16KB大小、时延为1个时钟周期、具备16个bank的SRAM,开发人员透过CUDA或者未来的Compute Shader、OpenCL实现对这块SRAM控制,而内核执行的线程结果可以在这里暂存实现高效的data re-use。
到这里大家应该都很清楚从技术的角度而言,CPU和GPU的发展都正面临着一个交叉点,前者因为各种原因不得不延缓“ILP/频率”这个免费午餐而转向多核技术,而后者因为制造技术的发展所新加入的晶体管构成的功能模块不仅仅限于可以在图形渲染上使用,包括不少可以并行化的运算也都能拿到GPU上高效的执行。这也就连带产生了市场争夺的问题——因为在很长的一段时间里,超级计算机、服务器这类被称作现金奶牛的市场都是由传统的CPU厂商提供运算部件,现在GPU厂商也要插一脚进来,而且他们在性能上的竞争力实在不容小瞥。
除了专业高性能科学运算领域外,在市场覆盖面更大的桌面领域,GPU涉足的通用计算也越来越让CPU厂商感到不少的隐忧,例如物理加速、视频处理、三维成品级渲染这类以往需要大量运算资源来完成的任务,GPU也都开始提供解决方案。目前的 PC市场普遍被认为进入了成熟阶段,这意味着市场容量在短时间内爆发性增长的可能性不大,所以GPU侵略桌面领域传统通用计算地位的结果,将只会是CPU的份额受到挤压。
对于一般的design house(设计公司)类型CPU厂商来说,这似乎不是什么大的问题,因为他们在营运上的成本主要是研发,而对于垂直型CPU厂商(IDM)来说,CPU份额的下降意味着自己的最强优势——产能将变成非常沉重的负资产。要避免这个问题的发生,最好的办法就是自己也推出类似的产品,而Larrabee就是Intel涉足视觉计算的答案#p#page_title#e#
Larrabee背后的设计思想其实是既要抢占到GPU编程的前沿阵地,又要提供一款可以广泛适用于高吞吐性应用领域的X86矢量处理器。而且,除可视化计算领域之外,这一架构在在高性能计算应用领域也有不错的前景。
实际上,英特尔把Larrabee看作是一种高吞吐的处理器,而不仅仅是一款GPU。负责该项目的高级工程师Larry Seiler强调了英特尔设计这种新架构的意图,他说,“Larrabee会对图形处理和超级计算领域产生革命性的影响。”不过,此次英特尔没有提及具体的核心数量、时钟频率和功耗,产品的发布时间也没有明确,大概会在2009年或2010年。
Larrabee最初的目标是推出一款PC用的高端GPU。通过进入高端图形处理器市场,英特尔希望把其在移动GPU市场中的优势延展到桌面游戏领域。
假如英特尔能够实现这一目标,我们相信它还会进一步把这个平台推向HPC市场。凭借其矢量性能和X86兼容性,Larrabee会成为其他高端加速器产品的重要竞争对手,这些产品包括NVIDIA的Tesla(以及其他支持CUDA编程开发环境的GPU),AMD的FireStream GPU, Cell处理器系统,ClearSpeed协处理器以及FPGA加速器等等。跟其他产品不同,Larrabee由于把CPU的逻辑部件已经整合在了芯片上面,所以不再需要外部的主处理器(host processor )。
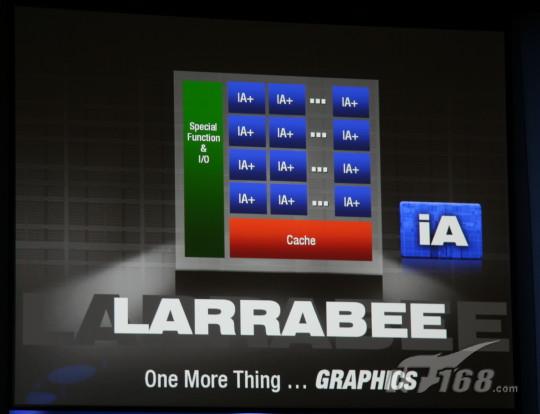
跟今天一般的GPU相比,Larrabee采用了不同的设计架构。该芯片将一些X86内核通过一条高速的环总线(ring bus)相互连接在一起,在每个方向都是512位宽。这些核心源自于英特尔的奔腾(Pentium)处理器,带有较短、顺序的执行流水线(execution pipelines)。每个内核可以同时执行多达四个线程,同时包含一个标量(scalar )和矢量单元( vector unit),后者每一个时钟周期可以执行16条32位运算。由于Larrabee从根本上来说是一种CPU架构,所有很多特性如context switching, preemptive multitasking, virtual memory和page swapping都已经集成在里面。而且由于线程管理是在软件中完成的,通过传统的并行化技术,延迟就很小了。
每一个内核包含一级指令缓存和数据缓存,同时芯片上也有二级缓存。二级缓存是由多个内核进行共享的,每个内核可以分派到256KB。跟GPU不同,缓存的一致性会在整个缓存体系中得到保持,因此,在处理器间通信( inter-processor communication )方面,可以让软件通过一个有效的机制来在应用线程之间共享数据。内存控制器(或者是控制器)也是在芯片上的,针对特定应用的功能单元也一样。
总的来看,一颗用于图形处理的Larrabee会用到很少的特定功能硬件。几乎所有的处理都是在X86内核上通过软件来完成的。在某些情况下,最明显的是图像纹理阴影处理上,英特尔增加了特定的功能硬件来增强性能。而且根据应用不同,如vertex shading, rasterization, pixel shading等,会采用不同的功能单元。因此,跟专用的硬件不同,通过通用芯片和软件,负载均衡会更容易实现,这也意味着当在晶圆上放置新的内核时,应用性能可以实现更加均衡地增长和扩展。
为了顺利进行图形领域,英特尔将支持DirectX和OpenGL ,以支持现有的应用。对于那些喜欢创新冒险的程序员来说,英特尔也会提供专门针对Larrabee的API ,这样,软件开发人员可以充分利用这一处理器的所有功能特性。对矢量指令集的访问也会通过C语言来实现。矢量单元会支持IEEE单精度和双精度浮点运算,同时也支持32位整数运算#p#page_title#e#
虽然Larrabee被定义为是一款众核芯片,但其第一个版本可能只有几十个内核,而不是象NVIDIA和AMD (ATI) 的GPU那样拥有好几百个核心。而且,就主频来说,Larrabee的性能可能还要低于传统的GPU产品。比如,即便每时钟周期(每核)可以执行多达16次单精度运算,一颗1.0 GHz 的Larrabee芯片需要62个内核,其性能才能相当于 NVIDIA和AMD 今年会发布的最新的万亿次(teraflop)GPU产品。相信英特尔会找到办法让Larrabee至少达到与竞争对手相当的性能水平。不过,除了性能,Larrabee在编程方面的优势会为其挣回不少分,特别是对于软件开发商来说,它们希望在开发新应用时有更多的灵活性。
在一个成熟的市场中引入一种全新的架构,是需要冒很大风险的,这一点相信英特尔在其安腾产品上已经体会到了。当然,英特尔在行业中确实拥有很强大的推动力量,在推动ISV和OEM支持Larrabee方面英特尔已经运作了一年多。笔者认为,其在图形领域取得成功的关键在于能否打入HPC市场。在某种程度上来看,Larrabee在高端科学计算方面可能比在更狭窄的可视化计算上更有价值。不管怎样,英特尔、AMD和NVIDIA之间的竞争会越来越有看头。
Larrabee Native编程模式类似于x86多核心架构。Larrabee Native编程中心是一个完整的C/C++编译程序,这种编译程序可以在在静止状态下向Larrabee x86指令集里收集程序。很多C/C++应用可以被重新编译成Larrabee可以识别的语言程序,而且可以在不加修饰的情况下正确执行这些应用。这无疑大大提升了程序开发人员在编写Larrabee程序时的效率,特别是在编写那些类似于常常出现在高性能运算环境中的x86代码。
目前Larrabee的两个局限:1.有些系统call porting的应用不能有效支持;2.目前的驱动架构仍然需要再编译。我们将会着重介绍Larrabee Native应用编程的三个重要方面:software threading(软件渲染)、SIMD vectorization以及主机与Larrabee之间的通讯。

Larrabee Native可以提供一种灵活的软件线程功能。这种架构层次的线程能力也就是我们常常提到的POSIX Threads API (P-threads)。我们已经将API进行了扩展,可以允许编程人员与某个特定的HW线程或者核心指定线程。
尽管P线程是一种非常强大的线程编程API,但是对于某些应用而言,P线程的creation以及switching成本代价通常情况下却非常高。为了缓解这种成本压力,Larrabee Native提供了一种基于分布式任务stealing scheduler的任务安排API,这种API非常轻。这种任务编程API的实际执行可以在Intel的Thread Building Blocks中看到。最终,Larrabee Native可以通过Larrabee Native C/C++编译程序中的OpenMP pragmas提供额外的线程编程支持。
对于Larrabee Native应用编程人员而言,所有的Larrabee SIMD矢量单元都是完全可编程的。Larrabee Native C/C++编译程序包括Larrabee版的Intel自动矢量化编程技术。需要编写Larrabee矢量单元的编程人员可以仅通过C++矢量intrinsics或者inline Larrabee集合代码轻而易举的编写这种程序。
在一种基于包括Larrabee的平台的CPU中,对于这个平台,Larrabee将会被OS驱动程序控制管理。Larrabee的library可以提供非常快的数据/信息传输协议,从而更好的在binaries间管理所有的存储数据传输和通讯。此外,某些从Larrabee应用binaries中访问的C/C++标准library功能的执行必须与主操作系统共享数据,特别是诸如read/write/open/close等在内的文件I/O功能。
除了非常高的吞吐量应用程序外,我们预测编程人员还将会利用Larrabee Native执行更高层次的编程模式,这种编程模式可能让平行编程的某些方面自动执行。比如说,Ct风格的编程模式、诸如Intel Math Kernel Library的高层次library API、physics API等等。目前的GPGPU编程模式同样可以通过Larrabee Native被重新执行。#p#page_title#e#
图形渲染管线本身就是一个Larrabee原生应用。由于Larrabee是一个以高级语言和工具写入的软件,Larrabee可以轻易扩展并增加极具创新的渲染能力。这里我们将会着重讨论三个图形管线的扩展实例。
渲染目标的读取(Render Target Read):由于Larrabee的图形渲染管线采用了软件frame buffer(帧缓冲),所以我们可以让其他一些程序员使用这些数据结构。而且值得一提的是,Larrabee渲染管线的某个无价值的扩展将会允许像素shader在被存储价值之前直接读取出来。这种能力可以用于各种各样的渲染,包括程序人员界定混合操作(programmer defined blending operations)、单通道基频模式映射(single-pass tone mapping)以及相关功能。
无规则透明度(Order Independent Transparency):这两种方法均不允许post-rendering area(粘贴渲染)效果,这种效果可能是不透明模式。下图描述的是如果这种效果在出现透明表面之后再被应用的话就会出现伪影(artifact)。
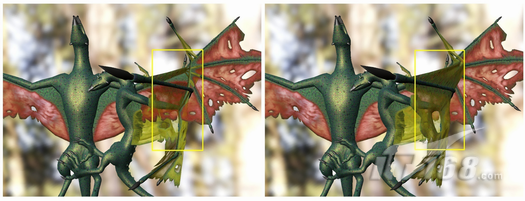

上图具有pre-resolve效果和不具有这种效果的透明性:上面的图像在应用雾补丁(fog patch)之前把几何和解析进行了分类处理;下边的图像应用雾补丁,使得图像表面透明,然后再解析图像。透过翅膀,右图中的雾是可见的,但是在左图中却看不到雾。
即使没有额外的专门逻辑单元,Larrabee一样可以通过将多透明表面存储到一个per-pixel spatial数据结构中的方式来支持无规则透明度(order independent transparency,OIT)。几何渲染之后,我们可以在透明表明执行效果,因为在分类以及解析图像片段之前,每个表面都保留这各自的深度(depth)和颜色(color)。
不规则阴影映射(Irregular Shadow Mapping):阴影映射(Shadow mapping)是一种非常流行的适时阴影接近技术(shadow approximation technique),不过大部分执行却通常会带来令人厌烦的锯齿伪影。过去人们就一直在探求一种可以消除伪影的办法。不规则阴影映射 (Irregular shadow mapping,ISM)为我们提供了一个非常好的解决办法,而且不会给应用编程带来任何额外的负重。
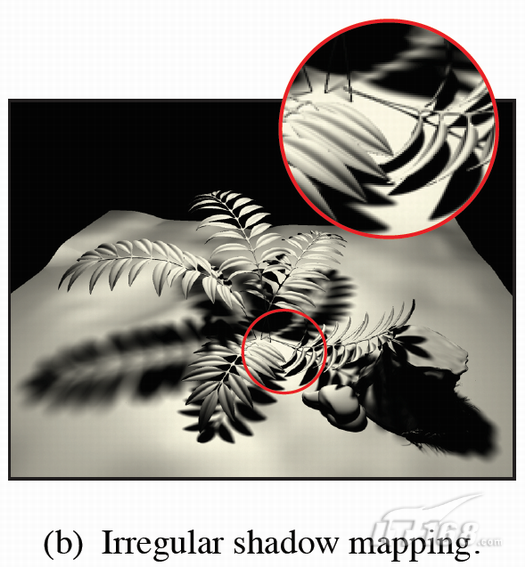
为了执行ISM,我们首先用可以用camera view模式捕捉到的深度样品并建立一个灯光视图(light view)模式三维数据结构。然后通过增加某个渲染阶段来制定化Larrabee的所有软件图形管线,这些渲染阶段可以执行light view ISM光栅。由于阴影映射是在某个准确位置被捕捉到的,所以被捕捉到的阴影映射是完全自由的。这种技术可以被用于操作适时硬阴影效果,正如上图所示。#p#page_title#e#
Larrabee也适合执行大量基于非光栅化的吞吐量应用。以下是一个关于某些采样可扩性和特性的简要说明。
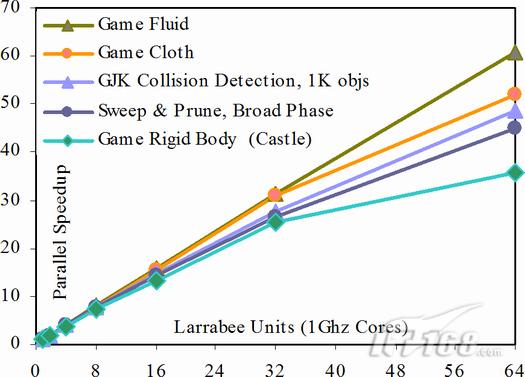
游戏物理可扩性性能(Game Physics Scalability Performance):上图说明Larrabee架构是可以满足互动式硬体(interactive rigid body)、流体(fluid)以及布料模拟运算法(cloth simulation algorithms)对性能的不断提升的要求。
游戏物理(Game Physics):我们已经了解了Larrabee在不同数量核心下的几款游戏物理工作量的可扩性模拟分析。上图表明某些游戏物理的硬体(rigid body)、流体(fluid)以及布料(cloth)基准和运算法则是可以被测量的。采用64核心设计的Larrabee可以取得高于50%的资源利用,而且在某些情况下,Larrabee达到了接近线性平行运算速度。游戏的rigid body模拟基于流行的10K大小的“城堡(castle)”破坏场景。游戏fluid模拟基于平滑粒子流体力学(smoothed particle hydrodynamics,SPH)运算法则。

上图描述的是Larrabee的适时光线追踪:一幅需要4M光线的1Kx1K样品图像。光线追踪器采用C++语言执行,某些手工编写(hand-coded)的集合代码可以用来执行诸如光线交叉(ray intersection)之类的重要操作。Kd-trees(线段树)一共为25MB,是由一帧一帧的图像组成的。一开始从视点发出的光线(primary rays)以及反射光线(reflection rays)被16光束测试。几乎所有的234K三角形图像对于一开始从视点发出的光线(primary rays)以及反射光线(reflection rays)的光线都是可见的。#p#page_title#e#
Larrabee的推出是大势所趋,在它问世之前,英特尔已经推出过多款显示芯片,最早期的包括本文中提到的i860以及在此之后的i740和各种整合图形芯片组。虽然Intel强调Larrabee是基于x86,但事实上LRBni(Larrabee的新指令集)和x86的差别相当大,只是这个套指令集在设计的时候就被设计为依赖于现有x86上而已。不过在英特尔公布LRBni的微代码编码方式之前,这个问题还真的不好弄清楚。
按照 heise.de的报道,英特尔的副总裁Joseph D. Schutz表示Larrabee会在2010年上半年推出,拥有低端到高端的完整产品线,但是具体的时间暂时不能确定,原因是这中间需要进行步进修改以及除错等步骤,相比之下开发人员能在早得多的时候获得原型版的Larrabee。
如果不出所料,Larrabee问世的时候,NVIDIA 和 AMD 都已经有了基于40nm的DirectX 11产品线,Larrabee首先需要在这个对决中站稳脚跟,而后才能讨论并行计算的问题,因为没多少人只是为了一块运算加速卡而购买产品,Intel 在Larrabee上的研发经费需要一个大容量的市场来分摊,这个市场仍然是游戏卡市场,要同时在游戏和计算上开辟新的市场,Larrabee的前路需要INTEL用坚定来铺垫


